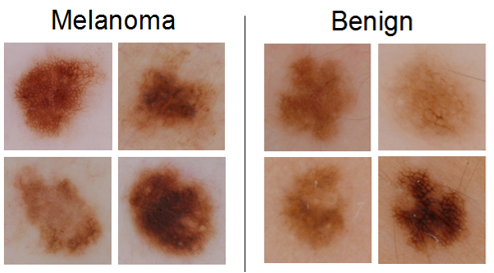
Goal
In this task, participants are asked to classify images as either malignant (melanoma) or non-malignant (non-melanoma).
Data
Lesion classification data includes the original image, paired with a gold standard (definitive) malignancy diagnosis.
Training Data
The Training Data file is a ZIP file, containing 900 dermoscopic lesion
images in JPEG format. All images are named using the scheme
ISIC_<image_id>.jpg, where <image_id> is a 7-digit
unique identifier. EXIF tags in the images have been removed; any remaining EXIF tags should
not be relied upon to provide accurate metadata.
Training Ground Truth
Download Training Ground Truth
The Training Ground Truth file is a single CSV (comma-separated value)
file, containing 2 columns and 900 rows. The first column of each row contains a string of
the form ISIC_<image_id>, where <image_id> matches the
corresponding Training Data image. The second column of each row contains either the string:
benign: representing non-malignantmalignant: representing malignant
Notes: Malignancy diagnosis data were obtained from expert consensus and pathology report information.
Participants are not strictly required to utilize the training data in the development of their lesion classification algorithm and are free to train their algorithm using external data sources.
Test Data
Given the Test Data file, a ZIP file of 379 images of the exact same format as the Training Data, participants are expected to generate and submit a file of Test Results.
Download Test Data: The Test Data file should be downloaded via the "Download test dataset" button below, which becomes available once a participant is signed-in and opts to participate in this phase of the challenge.
Submission Format
Test Results
The submitted Test Results file should not use the same format as
the Training Ground Truth file. Rather, the Test Results file should be a single CSV file,
containing 2 columns and 379 rows. The first column of each row should contain a string of
the form ISIC_<image_id>, where <image_id> matches a
corresponding Test Data image. The second column of each row should contain a floating-point
value in the closed interval [0.0, 1.0], where values:
0.0to0.5: represent some confidence in the prediction that the lesion in the image in non-malignant (i.e. benign), with relatively lesser values indicating relatively more confidence in non-malignancy> 0.5to1.0: represent some confidence in the prediction that the lesion in the image is malignant, with relatively greater values indicating relatively more confidence in malignancy
Note, arbitrary score ranges and thresholds can be converted to the range of 0.0 to 1.0, with a threshold of 0.5, trivially using the following sigmoid conversion:
1 / (1 + e^(-(a(x - b))))
where x is the original score, b is the binary threshold, and
a is a scaling parameter (often the measured standard deviation on a held-out
dataset).
Submission Process
Shortly after being submitted, participants will receive a confirmation email to their registered email address to confirm that their submission was parsed and scored, or to provide a notification that parsing of their submission failed (with a link to details as to the cause of the failure). Participants should not consider their submission complete until receiving a confirmation email.
Multiple submissions may be made with absolutely no penalty. Only the most recent submission will be used to determine a participant's final score. Indeed, participants are encouraged to provide trial submissions early to ensure that the format of their submission is parsed and evaluated successfully, even if final results are not yet ready for submission.
Evaluation
Submitted Test Results classifications will be compared to private (until after the challenge ends) Test Ground Truth. The Test Ground Truth was produced from the exact same source and methodology as the Training Ground Truth (both sets were randomly sub-sampled from a larger data pool).
Submissions will be compared using using a variety of common classification metrics, including:
However, participants will be ranked and awards granted based only on average precision.
Some useful resources for metrics computation include: